December 19, 2018 by akhilendra
How to do KNN with Python & Sci-Kit Learn

KNN or K-nearest neighbor is one of the easiest and most popular machine learning algorithm available to data scientists and machine learning enthusiasts.
In this post, we are going to implement KNN model with python and sci-kit learn library.
You can also implement KNN in R but that is beyond the scope for this post.
In this post, I am not going to discuss under the hood concepts of KNN and will only demonstrate the implementation.
If you want to learn more about the KNN, you can visit here.
Also, if you want to learn more about sci-kit learn librarywhich I am using here, click here.
Further, if you are interested in implementation of logisticregression using Azure ML studio, click here.
Alright, so let’s start with KNN implementation in python and with sci-kit learn library.
KNN with Python & Sci-Kit Learn
You can download the dataset from https://www.kaggle.com/ntnu-testimon/paysim1
Let’s import few libraries which are must for any machine learning algorithm in python and jupyter notebook.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as pltLet’s load the dataset using pandas
pay_data = pd.read_csv("PS_20174392719_1491204439457_log.csv")Now let’s review the head to verify the dataset.
pay_data.head()
| step | type | amount | nameOrig | oldbalanceOrg | newbalanceOrig | nameDest | oldbalanceDest | newbalanceDest | isFraud | isFlaggedFraud |
| 1 | PAYMENT | 9839.64 | C1231006815 | 170136 | 160296 | M1979787155 | 0 | 0 | 0 | 0 |
| 1 | PAYMENT | 1864.28 | C1666544295 | 21249 | 19384.7 | M2044282225 | 0 | 0 | 0 | 0 |
| 1 | TRANSFER | 181 | C1305486145 | 181 | 0 | C553264065 | 0 | 0 | 1 | 0 |
| 1 | CASH_OUT | 181 | C840083671 | 181 | 0 | C38997010 | 21182 | 0 | 1 | 0 |
| 1 | PAYMENT | 11668.1 | C2048537720 | 41554 | 29885.9 | M1230701703 | 0 | 0 | 0 | 0 |
pay_data.shape
(6362620, 11)
There are 6362620 row, that is observation and 11 variables, i.e. columns.
let’s drop unnecessary columns.
pay_data = .pay_data.drop(['nameOrig', 'nameDest', 'isFlaggedFraud'], axis = 1)Let’s divide our data set into two parts;
pay_data_fraud = pay_data[pay_data['isFraud'] == 1]
pay_data_nofraud = pay_data[pay_data['isFraud'] == 0]
pay_data_fraud.head()- Dataset where isFraud == 1. We will call it pay_data_fraud.
- Dataset where isFraud == 0. We will call it pay_data_nofraud.
| step | type | amount | oldbalanceOrg | newbalanceOrig | oldbalanceDest | newbalanceDest | isFraud |
| 1 | TRANSFER | 181 | 181 | 0 | 0 | 0 | 1 |
| 1 | CASH_OUT | 181 | 181 | 0 | 21182 | 0 | 1 |
| 1 | TRANSFER | 2806 | 2806 | 0 | 0 | 0 | 1 |
| 1 | CASH_OUT | 2806 | 2806 | 0 | 26202 | 0 | 1 |
| 1 | TRANSFER | 20128 | 20128 | 0 | 0 | 0 | 1 |
pay_data_nofraud.head()| step | type | amount | oldbalanceOrg | newbalanceOrig | oldbalanceDest | newbalanceDest | isFraud |
| 1 | PAYMENT | 9839.64 | 170136 | 160296.36 | 0 | 0 | 0 |
| 1 | PAYMENT | 1864.28 | 21249 | 19384.72 | 0 | 0 | 0 |
| 1 | PAYMENT | 11668.14 | 41554 | 29885.86 | 0 | 0 | 0 |
| 1 | PAYMENT | 7817.71 | 53860 | 46042.29 | 0 | 0 | 0 |
| 1 | PAYMENT | 7107.77 | 183195 | 176087.23 | 0 | 0 | 0 |
Let’s find out the dimension of the fraud & No Fraud data set.
pay_data_fraud.shape(8213, 8)pay_data_nofraud.shape(6354407, 8)This is a huge data set which will take lot of time for any model.Therefore let’s reduce it to so that it’s take optimum time for KNN.We have over 8000 values in fraud and so let’s take twice of those from no fraud data set.
pay_data_nofraud = pay_data_nofraud[0:16000]Let’s join both of these data sets to build the data set which will be used for running KNN model.
pay_data_nofraud_updated = pd.concat([pay_data_fraud, pay_data_nofraud], axis = 0)Let’s draw few charts for better understanding the data.
We are going to use seaborn and matplot lib in this analysis.
sns.relplot(x="type", y="amount", data=pay_data_nofraud_updated)
sns.relplot(x="type", y="amount",kind="line", data=pay_data_nofraud_updated)
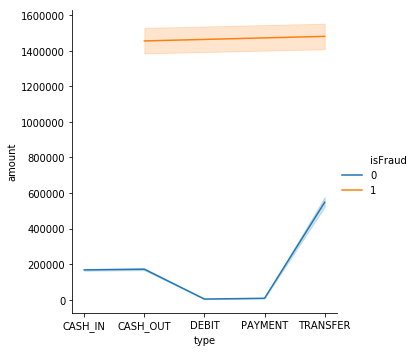
sns.relplot(x="type", y="amount",kind="line", hue="isFraud", data=pay_data_nofraud_updated)
sns.relplot(x="type", y="amount", hue="isFraud", data=pay_data_nofraud_updated)
sns.catplot(x="type", y="amount", data=pay_data_nofraud_updated);
With scikit-learn library, you cannot implement the machine learning algorithms on categorical columns. Therefore we cannot implement KNN on categorical columns in our data set. We will need to use label encoding and hot encoding in order to resolve this issue.
But first, we need to import label encoder and hot encoder modules in our session.
from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder
pay_data_nofraud_updated['type'] = pay_data_nofraud_updated['type'].astype('category')
#Integer Encoding the 'type' column
type_encode = LabelEncoder()
#Integer encoding the 'type' column
pay_data_nofraud_updated['type'] = type_encode.fit_transform(pay_data_nofraud_updated.type)
#One hot encoding the 'type' column type_one_hot = OneHotEncoder() type_one_hot_encode = type_one_hot.fit_transform(pay_data_nofraud_updated.type.values.reshape(-1,1)).toarray()
#Adding the one hot encoded variables to the dataset
ohe_variable = pd.DataFrame(type_one_hot_encode, columns = ['type_'+str(int(i)) for i in range(type_one_hot_encode.shape[1])])
pay_data_nofraud_updated = pd.concat([pay_data_nofraud_updated, ohe_variable], axis=1)
#Dropping the original type variable
pay_data_nofraud_updated = pay_data_nofraud_updated.drop('type', axis = 1)
pay_data_nofraud_updated.head()
|
step |
amount | oldbalanceOrg | newbalanceOrig | oldbalanceDest | newbalanceDest | isFraud | type_0 | type_1 | type_2 | type_3 | type_4 |
| 1 | 9839.64 | 170136 | 160296.36 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 1864.28 | 21249 | 19384.72 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 181 | 181 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 1 | 181 | 181 | 0 | 21182 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 1 | 11668.14 | 41554 | 29885.86 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
let’s check the data set for missing values.
pay_data_nofraud_updated.isnull().any() step True amount True oldbalanceOrg True newbalanceOrig True oldbalanceDest True newbalanceDest True isFraud True type_0 True type_1 True type_2 True type_3 True type_4 True dtype: bool
There are missing values in all of the above column with True. For this analysis, we will simply replace the missing value with 0 but you can explore more ideas.
pay_data_nofraud_updated = pay_data_nofraud_updated.fillna(0)
In this KNN model;
- dependent variable is isFraud
- It contain 0 and 1
- Remaining columns/variables are independent variables
- Creating ind_var for independent variable & dep_var for dependent variable.
ind_var = pay_data_nofraud_updated.drop('isFraud', axis = 1).values
dep_var = pay_data_nofraud_updated['isFraud'].values
print(ind_var)
[[1.00000000e+00 9.83964000e+03 1.70136000e+05 ... 0.00000000e+00
0.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.86428000e+03 2.12490000e+04 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]
[1.00000000e+00 1.81000000e+02 1.81000000e+02 ... 0.00000000e+00
0.00000000e+00 1.00000000e+00]
...
[7.43000000e+02 6.31140928e+06 6.31140928e+06 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]
[7.43000000e+02 8.50002520e+05 8.50002520e+05 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]
[7.43000000e+02 8.50002520e+05 8.50002520e+05 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]]
print(dep_var) [0. 0. 1. ... 1. 1. 1.]
Let’s import split model from sklearn and create training & testing data sets.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(ind_var, dep_var, test_size = 0.3, random_state = 42, stratify = dep_var)
from sklearn.neighbors import KNeighborsClassifier #Initializing the KNN classifier with 3 neighbors knn_class = KNeighborsClassifier(n_neighbors=3) #Fitting the classifier on the training data knn_class.fit(X_train, y_train) #Extracting the accuracy score from the test sets knn_class.score(X_test, y_test)
0.9859851607584501
import numpy as np
from sklearn.model_selection import GridSearchCV
#grid with 1 to 24 neighbours
grid = {'n_neighbors' : np.arange(1, 25)}
#Initializing KNN classifier
knn_classif = KNeighborsClassifier()
#cross validation
knn = GridSearchCV(knn_classif, grid, cv = 10)
knn.fit(X_train, y_train)
#Extracting best parameter
knn.best_params_
#Extracting the accuracy score for optimal number of neighbors
knn.best_score_
0.9842763128837065
#standardization
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
#Setting up the scaling pipeline
pipe = [('scaler', StandardScaler()), ('knn', KNeighborsClassifier(n_neighbors = 1))]
pipe_ord = Pipeline(pipe)
#Fitting the classfier to the scaled dataset
knn_classifier_scaled = pipe_ord.fit(X_train, y_train)
#Extracting the score
knn_classifier_scaled.score(X_test, y_test)
0.9965993404781534
KNN Model Summary
This KNN model is exhibiting high accuracy but this is a very basic model. If you are looking to further explore KNN, i will suggest you to use different techniques to handle missing values and try different parameters in the model.
Please leave your comment and let me know your feedback.
M. Venkatakumar - February 22, 2019 @ 11:42 am
Hi
https://akhilendra.com">akhilendra - February 22, 2019 @ 1:31 pm
Hi Venkat, let me know if you need any information.