November 10, 2019 by akhilendra
What is Activation Function & Why you need it in Neural Networks

Unlock the Power of Generative AI!
Master prompt engineering and dive deep into the future of AI with our expert-led program. Learn how to create advanced AI solutions, from text generation to chatbots, using cutting-edge techniques and tools like GPT models.
 Join Now and take the first step towards becoming an AI innovator!
Join Now and take the first step towards becoming an AI innovator!
In order to build a deep neural network, you need to understand activation functions and how they influence the quality of your model.
So if you came across activation functions while working on deep learning and wondering what is activation function or why do we even need to use them in our deep learning models? This post will help you.
In this post we are going to talk about activation function and why we should use activation functions in our neural networks.
If you are planning to work in deep learning & build models for image, video or text recognition, You must have very good understanding of activation function and why they are required.
I am going to cover this topic in a very non-mathematical and non-technical way so that you can relate to it and build an intuition.
After that if you need, you can explore mathematical or technical explanations based on your interest, but this meant for beginners, so I have kept it very simple.
Let’s take a step back and see why we even need deep learning models; we need them to solve complex problems. You are essentially building a model for pattern recognition.
It will involve learning images, texts or videos.
A neural network without nonlinear activation function won’t be powerful enough to learn complex features.
Remember, core concept is that your model will act as “universal approximator” which essentially means that it should be capable of learning or approximating the behavior. A linear model could serve purpose under some simpler conditions but usually it will fail to learn complex features.
What is Activation function
Activation functions are required to add nonlinearity to a function or model. In simple terms when you build a neural model, it looks something like;
z= wx+b
where w= weights and b are bias while x is your input.
It is a linear function which essentially means it will produce a linear output.
And we need nonlinear function to add nonlinearity. Activation function will take input of a layer, convert it and supply this output to next layer as input.
But question is why we bother to add nonlinearity, non-linear is required to so that your function can learn complex problems. Look at this picture;

This is a linear function; it can only learn so much.
Why Activation functions are needed in Deep learning models
As you can see, it cannot cover maximum ground and cannot map most of the features. If you don’t use activation functions, you are essentially NOT building a deep learning model.
Output of multiple layers without a non-linear activation function would still be a linear transformation.
It’s like your model is receiving a value of 1 and producing a value of 1. Even if you add multiple hidden layers, it will behave like a single layer model because output of all layers will be essentially same.
Now look at this;

As you can see, this model is quite flexible and learn more properties and features.
Activation function decide if a neuron should be fired for a given input or not? For example- if you are working on a classification problem, less than 0.5 will be classified as 0 and more than 0.5 will be classified as 1. In this case, 0 and 1 will represent classes. So, if your model needs to classification something into human or not, these classes will represent that.
They convert input of layer 1 to output which is then used as input for layer 2 in a model.
They are also used in back propagation where we need to update our weights accordingly but that is something for later.
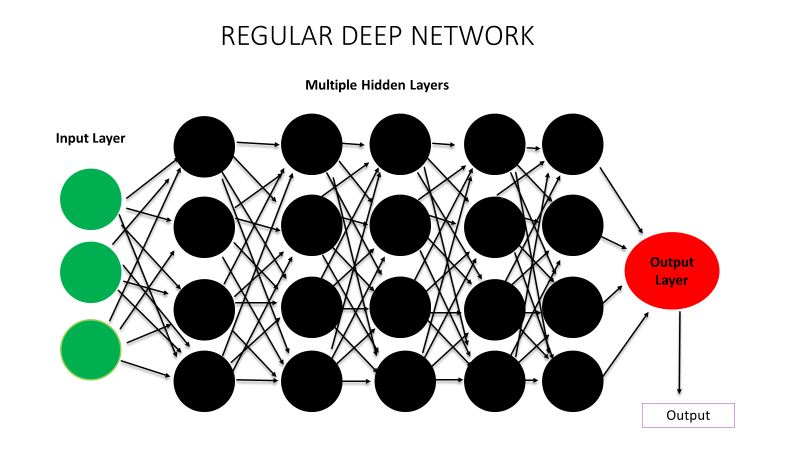
Now to put it simply in the context of deep learning model, have a look at this model (deep learning model's illustration);

Actual Artificial neural network model's representation

This is your regular deep learning model. Now let’s say we are using this for image classification, and this is the image it is working on;

All these red squares in this picture represent your features. In absence of activation function or non-linearity, all your neurons will be triggered and all of them might end up learning same features because there won’t be anything to inform neurons whether they need to activate or not.
Whereas in presence of activation function or non-linearity, activation function will tell neurons whether they need to fire up or not.

These red circles in this picture represent individual neurons.
So, in presence of an activation function, they are only fired when they need to learn a feature. And that’s why activation model helps in being universal approximator.
So, in your model, some neuron will learn eye, some will nose and some other will learn something else. Overall your model will be able to learn this picture or for that matter, any other content.
As mentioned earlier, I have avoided technical or mathematical jargon, but feel free to add your comment to add more values.
I have essentially tried to answer why we need activation functions. They are critical and very important to build deep learning models but remember they are optional, you can still go ahead and create a model without activation function, it’s just that all of your neuron may end up learning only limited features therefore NOT behaving like a deep learning model but a simple single layer models, only learning few features.Most common activation functions are;
- Relu
- Leaky Relu
- Sigmoid
- Tanh
- Softmax
I will cover these activation functions in some other post.
Please leave your comments and questions. And yes, don’t forgot to share it with your friends.
Leave a Reply